Introduction
I often find myself having to run code for some arbitrary set of different parameters.
This can be done with nested for loops. This is not pretty, and poses a challenge for paralleization and progress tracking. In this blog post, I solve this in python with tqdm for progress bars and multiprocess for parallelizing.
Weather example
Assume we want to evaluate a model p_rain(rained, temp) that estimates probability of rain tomorrow given the current weather condition over the following parameter space:
parameters = {"rained": (True, False), "temp": (15, 20, 25, 30)}
A basic attempt with nested for loops:
result = []
for rained in parameters["rained"]:
for temp in parameters["temp"]:
result.append(
(rained, temp, p_rain(rained, temp)))
Note how more paramters makes loop nesting deeper!
With tqdm a progress indicator is added:
result = []
for rained in tqdm(parameters["rained"]):
for temp in parameters["temp"]:
result.append(
(rained, temp, p_rain(rained, temp)))
However, it will only update on 0, 50, and 100% steps as there are only 2 values of rained. Moving tqdm to the inner loop will give 2 fast progress bars instead one slow one. Neither is good, and the order of loops can make a big difference.
Next, adding some parallelization with multiprocess.Pool.map:
pool = multiprocess.Pool()
result = []
for rained in tqdm(parameters["rained"]):
result.extend(
pool.map(
lambda temp:
(rained, temp, p_rain(rained, temp)),
parameters["temp"],
)
)
The parallelization now has a bottleneck in waiting for the outer loop. And to an even larger extent, the ordering of loops matter. While this setup can work, it is easy to do better!
What is needed, is a flat list of all parameters, that some function that achieves this:
> flat_dicts({"rained": (True, False), "temp": (15, 20, 25)})
[{"rained": True, "temp": 15},
{"rained": True, "temp": 20},
{"rained": True, "temp": 25},
{"rained": False, "temp": 15},
{"rained": False, "temp": 20},
{"rained": False, "temp": 25}]
With this the above loops can be reduced to a single loop, and tqdm and pool can work as expected.
Cartesian product
With itertools.product all combinations can easily be generated:
>>> list(product((True, False), (10, 15, 25)))
[(True, 10), (True, 15), (True, 25), (False, 10), (False, 15), (False, 25)]
In the rain example dictionary, make the product on parameter values, then loop over each parameter tuple and add keys:
def flat_lists(parameters):
return {k: v for k, v in zip(parameters.keys(), i)} for i in product(*parameters.values())
>>> list(flat_dicts({"rained": (True, False), "temp": (15, 20, 25)}))
[{'rained': True, 'temp': 15},
{'rained': True, 'temp': 20},
{'rained': True, 'temp': 25},
{'rained': False, 'temp': 15},
{'rained': False, 'temp': 20},
{'rained': False, 'temp': 25}]
wich is exactly what we hoped to achieve.
Putting it all together
First define a product function and a looper
from itertools import product
from tqdm import tqdm
import multiprocess as mp
def loop_pars(pars, fun):
tasks = list(flat_dicts(pars))
return tqdm(pool.imap_unordered(lambda x: {**x, "result": fun(**x)}, tasks), total=len(tasks))
To get this working, tqdm must know the total iteration count, and use imap to get data once it’s finished.
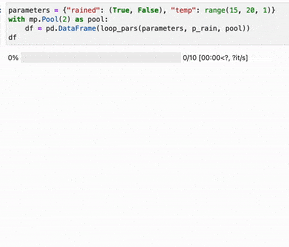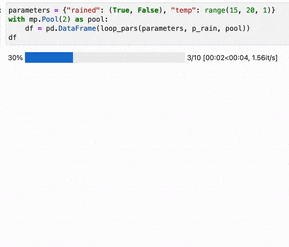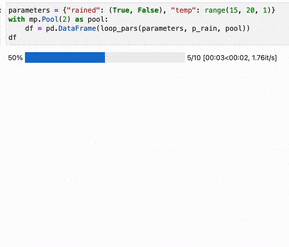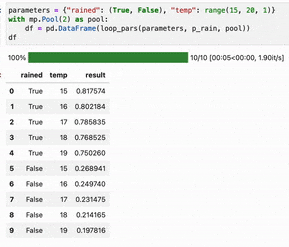
And now we can run a simple test (with a terribly inaccurate logistic weather model):
import time
def p_rain(rained, temp):
time.sleep(1)
return 1/(1+np.exp(0.1*(temp-5*(1+5*rained))))
parameters = {"rained": (True, False), "temp": range(15, 20, 1)}
with mp.Pool(2) as pool:
df = pd.DataFrame(loop_pars(parameters, p_rain, pool))
df
Here, execution was slowed down by limiting to 2 processes and sleeping. The result running in a jupyter notebook using tqdm.notebook.:
Summary
Using a the cartesian product allows flattening an otherwise deeply nested loop. Not only does this make code prettier, but also easier to parallelize.