Advent of Code 2022
I will do this years Advent of Code 2022 in vanilla (only included libraries) python 3.10.4. I’ve joined the challenge a few times before - but never finished. Let’s see how many days I manage this round :D
NOTE: This blog contains spoilers - use it responsibly.
I’ve hidden the details for each day behind expand details blocks if you want to see only some solutions.
While my solutions do not use external libraries, I sometimes add graphics made with matplotlib.
Template
In general, these tasks require input data to be read in and be processed in two different parts. Here is the pathon template I use to get started:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""Advent of code day XX - """
def read_data(path: str) -> list:
result = []
with open(path, "r") as f:
for line in f.readlines():
result.append(line)
return result
def part1(data: list):
return
def part2(data: list):
return
if __name__ == "__main__":
DAY = "XX"
exdata = read_data(f"day{DAY}_example.txt")
indata = read_data(f"day{DAY}_input.txt")
print("PART 1")
print("\texample", part1(exdata))
print("\tinput", part1(indata))
print("PART 2")
print("\texample", part2(exdata))
print("\tinput", part2(indata))
I’ll keep my code on this github repository, most of the code will appear in this blog post.
Learnings
I learned a few useful things on these challenges so far:
itertools.takewhile- Iterate while predicate is True- The sign of x:
(x > 0) - (x < 0) - Transpose for list of lists:
tuple(zip(*data)) - Like
sum(x)but for products:functools.reduce(operator.mul, x, 1) - The use of
functools.cmp_to_keyand key functions to change howsort,max, and similar functions work in python - To get both max and min over two dimensions of data like
[(x0, y0), (x1, y1), ...]one can use(min0, max0),(min1, max1) = map(lambda x: (min(x), max(x)), zip(*data)) - It’s easy and useful to print unicode characters
sand="🟨" re.splitis a great when parsing text input
Day 01 - Counting calories
Click to expand Day01 solution
Lines in a group have a single integer, blank lines separate groups.
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
read_sums parses the data, aggregates groups, and returns the list of sums.
def read_sums(path):
result = [0] # Start with single empty sum
with open(path, "r") as f:
for line in f.readlines():
if not line.strip():
result.append(0) # Add new empty sum
continue
result[-1] = result[-1] + int(line)
return result
Part 1
Task: Find the group with the largest sum.
Solution: Take the maximum of the list of sums
max(read_sums("day01_input.txt"))
Part 2
Task: Find the three largest groups.
Solution: Sort the list and summing the last 3 items:
sum(sorted(read_sums("day01_input.txt"))[-3:])
Day 02 - Rock Paper Scissors
Click to expand Day02 solution
Data: rows with games, the first column is the opponent move, and the second is the player move.
Move encoding: Rock, paper, and scissors is A, B, C for opponent, and X, Y, Z for player.
A Y
B X
C Z
read_strats parses the data and converts character representation to 0, 1, 2
def read_strats(path: str) -> list[int]:
with open(path, "r") as f:
return [
(ord(i) - ord("A"), ord(j) - ord("X"))
for i, j in (x.split() for x in f.readlines())
]
Part 1
Task: Count score for rock paper scissors games.
Score: Player move (1 for rock, 2 for paper, and 3 for scissors), plus 0 for loss, 3 for draw and 6 for win.
The score function computes the score for a single game:
def score(i, j):
return j + 1 + [[3, 0, 6], [6, 3, 0], [0, 6, 3]][j][i]
With this the total score is
def part1(strats: list[int]) -> int:
return sum(map(lambda i: score(*i), strats))
Part 2
Task: count score as above but now the second column states X=loss, Y=draw, Z=win.
Using transform the second column is transformed to the old format:
def transform(i, j):
return [[2, 0, 1], [0, 1, 2], [1, 2, 0]][j][i]
and then the total score (using part1 on the transformed data) is
def part2(strats: list[int]) -> int:
return part1(map(lambda x: (x[0], transform(*x)), strats))
Day 03 - Rucksack Reorganization
Click to expand Day03 solution
Each row of data is a rucksack with a string of characters [a-zA-Z].
vJrwpWtwJgWrhcsFMMfFFhFp
jqHRNqRjqzjGDLGLrsFMfFZSrLrFZsSL
PmmdzqPrVvPwwTWBwg
wMqvLMZHhHMvwLHjbvcjnnSBnvTQFn
ttgJtRGJQctTZtZT
CrZsJsPPZsGzwwsLwLmpwMDw
Each character corresponds to a priority: a=1,…, z=27, A=27,…, Z=52.
def priority(c: chr) -> int:
return (ord(c) - ord("A") + 27) if c.isupper() else (ord(c) - ord("a") + 1)
With this sack data is read with read_sacks.
def read_sacks(path: str)->list[list[int]]:
result = []
with open(path, "r") as f:
for line in f.readlines():
result.append(list(map(priority, line.strip())))
return result
Part 1
Task: sum priority of items unique in first and second half of rucksack.
Part 1 is solved by summing the set intersections of the first and second part of the sacks:
def part1(sacks: list[list[int]]) -> int:
return sum(
map(lambda x: sum(set(x[: len(x) // 2]).intersection(x[len(x) // 2 :])), sacks)
)
Part 2
Task: sum priority of items unique to three consecutive rucksacks.
This part is solved by summing the intersections of consecutive sacks, as follows:
def part2(sacks: list[list[int]]) -> int:
return sum(
map(
lambda x: sum(
set(sacks[x]).intersection(sacks[x + 1]).intersection(sacks[x + 2])
),
range(0, len(sacks), 3),
)
)
Day 04 - Camp Cleanup
Click to expand Day04 solution
Each row shows a pair separated by ,, each entry is a range low-high.
2-4,6-8
2-3,4-5
5-7,7-9
2-8,3-7
6-6,4-6
2-6,4-8
With this sack data is read with read_pairs.
def read_pairs(path: str):
result = []
with open(path, "r") as f:
for line in f.readlines():
result.append(list(map(int, line.replace("-", ",").split(","))))
return result
Part 1
Task: Count pairs where one pair fully overlaps with the other
Solution: check if one pair overlaps the other in either order.
def count_contained(pairs: list[list[int]]) -> int:
return sum(
map(
lambda x: (x[2] >= x[0] and x[3] <= x[1])
or (x[0] >= x[2] and x[1] <= x[3]),
pairs,
)
)
Part 2
Task: Count overlapping pairs
Solution: Check if range bounds overlap in any way
def count_overlaps(pairs: list[list[int]]) -> int:
return sum(
map(
lambda x: (x[1] >= x[2] and x[1] <= x[3])
or (x[3] >= x[0] and x[3] <= x[1]),
pairs,
)
)
Day 05 - Supply Stacks
For me the whole challenge here was to parse the data.
Click to expand Day05 solution
The data is split into two parts separated by a blank line. In the first part, stacks of items are listed in columns, with column index on the last row (this index can be ignored). Items are on the form [X] where X is a single character item id. In the second part a sequence of moves with item count count, source column, destination column are listed.
[D]
[N] [C]
[Z] [M] [P]
1 2 3
move 1 from 2 to 1
move 3 from 1 to 3
move 2 from 2 to 1
move 1 from 1 to 2
The two parts are read in and processed with read_stacks:
def read_stacks(path: str) -> tuple[dict[int, list[chr]], list[list[int]]]:
stacks = defaultdict(list)
moves = []
with open(path, "r") as f:
lines = f.readlines()
# Read stacks
for j, line in enumerate(lines):
if line == "\n":
break
for i in range(len(line) // 4):
stacks[i].append(re.sub("[^A-Za-z]+", "", line[i * 4 : i * 4 + 4]))
# Read moves
for line in lines[j + 1 :]:
moves.append([int(i) for i in re.sub("[^0-9]+", " ", line).split()])
return {k + 1: [i for i in v if i] for k, v in stacks.items()}, moves
Part 1
Task: apply the moves and list the top item in the stack
The moves are applied in sequence using apply_moves.
def apply_moves(
stacks: dict[int, list[chr]], moves: list[list[int]], reverse: bool
) -> str:
for n, s, d in moves:
sub = stacks[s][:n]
stacks[d] = (sub[::-1] if reverse else sub) + stacks[d]
stacks[s] = stacks[s][n:]
return "".join([v[0] for k, v in stacks.items()])
The reverse option is used to reorder the stack to work with the specification. For this task reverse=True.
Part 2
Task: same but with different ordering of added items.
This is solved with the same apply_moves function with reverse=False.
Day 06 - Tuning Trouble
Click to expand Day06 solution
5 examples are given:
7 mjqjpqmgbljsphdztnvjfqwrcgsmlb
5 bvwbjplbgvbhsrlpgdmjqwftvncz
6 nppdvjthqldpwncqszvftbrmjlhg
10 nznrnfrfntjfmvfwmzdfjlvtqnbhcprsg
11 zcfzfwzzqfrljwzlrfnpqdbhtmscgvjw
Task: find message start - the first instance of four different consecutive characters.
Solution: generate the length of the set of n character spans until it equals n. For this itertools.takewhile is very useful.
from itertools import takewhile
def find_start(message: str, n: int) -> int:
return n + sum(
1
for _ in takewhile(
lambda x: x != n,
map(lambda x: len(set(message[x - n : x])), range(n, len(message))),
)
)
Plugging in n=4 into this gives the correct solution for part 1, and part 2 likewise with n=14.
Day 07 - No Space Left On Device
Click to expand Day07 solution
A file system is explored using cd and ls. The first cd is always to / and ls are always in current directory. Lines with commands starts with $. Listings of directories start with dir, and listings of file starts with file size.
$ cd /
$ ls
dir a
14848514 b.txt
8504156 c.dat
dir d
$ cd a
$ ls
dir e
29116 f
2557 g
62596 h.lst
$ cd e
$ ls
584 i
$ cd ..
$ cd ..
$ cd d
$ ls
4060174 j
8033020 d.log
5626152 d.ext
7214296 k
The code is read into a tree strucutre of nested dictionaries using read_tree. For files the value is the filesize int instead of a dictionary. I based the thinking here on my Tree Hack blog post.
def read_tree(path: str) -> dict:
tree = {}
cwd = []
with open(path, "r") as f:
t = tree
for line in f.readlines()[1:]:
split = line.split()
if split[0] != "$":
# Add file or directory
t[split[1]] = {} if split[0] == "dir" else int(split[0])
elif split[1] == "cd":
dest = line.split()[-1]
# Update current working directory
cwd = cwd[:-1] if dest == ".." else (cwd + [dest])
t = tree
for c in cwd: # Jump to the right directory in the tree
t = t[c]
return tree
with the tree structure in place, one can traverse the tree and collect the total size of each directory.
def dir_size(tree: dict, base: str = "/") -> dict:
result = {base: 0}
for k, v in tree.items():
if isinstance(v, int):
result[base] += v
continue
key = base + "/" + k
t = dir_size(v, base=key)
result.update(t)
result[base] += t[key]
return result
The data input for the problems is the output of dir_size(read_data("input.txt")).
Part 1
Task 1: Find sum of directory sizes less than 100000
Solution: sum sizes ignoring anything smaller than the threshold:
def part1(data: dict, thresh=100000) -> int:
return sum(v for k, v in data.items() if v < 100000)
Part 2
Task 2: Find smallest directory that when removed leaves 30000000 free storage of a total of 70000000.
Solution: Take smallest element of items where 70000000-used+size>30000000
def part2(data: dict, total=70000000, req=30000000) -> int:
return min(v for k, v in data.items() if total - data["/"] + v > req)
Day 08 - Treetop Tree House
Click to expand Day08 solution
Data are heights of trees on a square grid.
30373
25512
65332
33549
35390
The maps are read into a list of list of ints.
def read_map(path: str) -> tuple[tuple[int]]:
"""Read in data into 2D int array"""
with open(path, "r") as f:
return tuple(tuple(map(int, i.strip())) for i in f.readlines())
Part 1
Task: Count number of visible trees from the edge.
Trees are not visible if behind trees of same or lower height. The count is found as the sum of True values in a visibility matrix made by OR-ing together partial visibility matrices for each direction.
def T(data: tuple[tuple[int]]) -> tuple[tuple[int]]:
"""Transpose list of lists"""
return tuple(zip(*data))
def vor(x: list[bool], y: list[bool]) -> list[bool]:
"""Elementwise or of lists x and y"""
return tuple(i or j for i, j in zip(x, y))
def vx(x: tuple[int]) -> tuple[bool]:
"""Visibility for each element in row x"""
return [True] + [all(j < x[i] for j in x[:i]) for i in range(1, len(x))]
def vis(data: tuple[tuple[int]]) -> tuple[tuple[bool]]:
"""Visibilities for both directions in each row in data"""
return tuple(vor(vx(x), vx(x[::-1])[::-1]) for x in data)
def visibility(data: tuple[tuple[int]]) -> tuple[tuple[bool]]:
"""Visibility ORed for rows and columns in data"""
return tuple(vor(i, j) for i, j in zip(vis(data), T(vis(T(data)))))
def sum_visibility(data: tuple[tuple[int]]) -> int:
"""Sum visibilities"""
return sum(sum(i) for i in visibility(data))
Part 2
Task: find maximum scenic score (product number of tree visible in each direction)
Here, for each tree the number of consecutive shorter trees is counted and multiplied together for each direction.
This task took quite some time to debug, I think I didn’t parse the instructions correctly…
def count(v0: int, v: list[int]) -> int:
"""Count trees"""
n = 0
for x in v:
n += 1
if v0 <= x:
break
return n
def scenic(data: tuple[tuple[int]]) -> int:
"""Compute scenic score for each tree"""
scenic_scores = dict()
data_t = T(data)
r = len(data)
c = len(data[0])
maxx = 0
for i in range(r):
for j in range(c):
x = data[i][j]
maxx = max(
maxx,
count(x, data[i][:j][::-1])
* count(x, data[i][j + 1 : c])
* count(x, data_t[j][:i][::-1])
* count(x, data_t[j][i + 1 : r]),
)
return maxx
Day 09 - Rope Bridge
Click to expand Day09 solution
Input data consists of moves with a direction (U,D,R,L) and a number of steps
R 4
U 4
L 3
D 1
R 4
D 1
L 5
R 2
The task is to move the head of a rope according to the moves, and track how the tail trails.
def read_moves(path: str) -> list[tuple[str, int]]:
with open(path, "r") as f:
return list(
map(lambda x: (x[0], int(x[1])), (line.split() for line in f.readlines()))
)
The solution for part2 also solves part1 so I refactored simualte accordingly. As I had several bugs, I added a handy printer function to print the rope and locations visited by the tile:
def printer(x: list[list[int]], hashes: bool = False):
c = ["#" if hashes else str(i) for i in range(len(x))]
if not hashes:
c[0] = "H"
sx = [s[0] for s in x]
minx, maxx = min(sx), max(sx)
sy = [s[1] for s in x]
miny, maxy = min(sy), max(sy)
for j in list(range(miny, maxy + 1))[::-1]:
print(
"".join(
[
c[x.index([i, j])] if [i, j] in x else "."
for i in list(range(minx, maxx + 1))[::-1]
]
)
)
The simulation is fairly straight forward, once you decode the instructions…
def sign(x: int) -> int:
return (x > 0) - (x < 0)
def simulate(data, n=9, show=False):
x = [[0, 0] for i in range(n + 1)]
DELTA = {"U": (0, 1), "D": (0, -1), "R": (-1, 0), "L": (1, 0)}
visited = {(0, 0)}
for direction, steps in data:
if show:
print(f"=== {direction} {steps} ===")
d = DELTA[direction]
for step in range(steps):
# Update head
x[0] = [x[0][0] + d[0], x[0][1] + d[1]]
# Update tail
for i in range(1, len(x)):
dt = [x[i - 1][0] - x[i][0], x[i - 1][1] - x[i][1]]
if abs(dt[0]) > 1 or abs(dt[1]) > 1:
x[i][0] += sign(dt[0])
x[i][1] += sign(dt[1])
visited.add(tuple(x[-1]))
if show:
printer(x)
if show:
print("VISITED")
printer(list(list(x) for x in visited), hashes=True)
return len(visited)
With this code the solutions are comptuted by running:
print("part 1:", read_moves("input.txt"), 1)
print("part 2:",read_moves("input.txt"), 9)
The printer gives this expected output for the tail visits for the longer example in part 2.
#.....................
#.............###.....
#............#...#....
.#..........#.....#...
..#..........#.....#..
...#........#.......#.
....#......#.........#
.....#..............#.
......#............#..
.......#..........#...
........#........#....
.........########.....
Day 10 - Cathode-Ray Tube
Click to expand Day10 solution
Data is instruction lists with noop (takes 1 cycle) and addx (takes 2 cycles). addx dx adds dx to the register x.
noop
addx 3
addx -5
The data is parsed to cycle count and dx for each instruction in read_program.
def read_program(path: str) -> list[tuple[int, int]]:
with open(path, "r") as f:
return [
(1 if "noop" in l else 2, 0 if "noop" in l else int(l.split()[1]))
for l in f.readlines()
]
Next, the program is executed using run_programto track cycle count and x after each instructions. x starts at 1.
def run_program(prog: list[tuple[int, int]], x: int = 1) -> list[tuple[int, int]]:
y = [[0, x]]
for dt, dx in prog:
y.append((y[-1][0] + dt, y[-1][1] + dx))
return y
Part 1
Task: Get cycle count * x for every 40th cycle starting at 20
The result is obtained by applying part1 to the output of run_program.
def part1(out: list[tuple[int, int]]) -> int:
result = 0
for q in range(20, out[-1][0], 40):
*_, x = (q * v for (t, v) in out if t < q)
result += x
return result
Part 2
Task: Draw pixels when x is within +-1 of cycle MOD 40.
The result is obtained by applying part2 to the output of run_program.
def part2(prog: list[tuple[int, int]]) -> str:
idx = 0
result = [" "] * 240
for s in range(240):
r, c = divmod(s, 40)
if prog[idx][1] - 1 <= c <= prog[idx][1] + 1:
result[s] = "█"
if s > prog[idx][0]:
idx += 1
return "\n".join("".join(result[i * 40 : (i + 1) * 40]) for i in range(6))
This part is very satisfying as you get nice output! For the example:
██ ██ ██ ██ ██ ██ ██ ██ ██ ██
███ ███ ███ ███ ███ ███ ███
████ ████ ████ ████ ████
█████ █████ █████ █████
██████ ██████ ██████ ████
███████ ███████ ███████
and for my input:
███ ████ ███ ██ ████ ████ ██ ███
█ █ █ █ █ █ █ █ █ █ █ █
█ █ █ ███ █ █ ███ █ ███
███ █ █ █ █ ██ █ █ █ █ █
█ █ █ █ █ █ █ █ █ █ █ █
█ ████ ███ ███ ████ ████ ██ ███
Day 11 - Monkey in the Middle
Click to expand Day11 solution
Monkeys process their stack of worries and perform an operation on them, divides the results, and passes it on to another monkey depending on divisibility.
Monkey 0:
Starting items: 79, 98
Operation: new = old * 19
Test: divisible by 23
If true: throw to monkey 2
If false: throw to monkey 3
Monkey 1:
Starting items: 54, 65, 75, 74
Operation: new = old + 6
Test: divisible by 19
If true: throw to monkey 2
If false: throw to monkey 0
...
I read the data with the read_monkey. This function defines the operation and test as lambdas to be applied later. If divby is 1 the // at the end of the operation is avoided altogether (useful in part 2). Inspected is a counter that should be incremented for every action the monkey takes.
def read_monkeys(path: str, divby: int = 3) -> list[dict]:
result = []
with open(path, "r") as f:
for monkey in f.read().split("\n\n"):
monkey_data = [m.strip() for m in monkey.split("\n") if m.strip()]
result.append(
{
"monkey": int(monkey_data[0].replace(":", "").split()[-1]),
"stack": list(
map(
int,
monkey_data[1].replace("Starting items: ", "").split(","),
)
),
"inspected": 0,
"mod": int(monkey_data[3].replace("Test: divisible by ", "")),
"operation": eval(
"lambda x: ("
+ monkey_data[2]
.replace("Operation: new = ", "")
.replace("old", "x")
+ ")"
+ ("" if divby == 1 else f"//{divby}")
),
"test": eval(
f"lambda x: ({int(monkey_data[4].split()[-1]), int(monkey_data[5].split()[-1])})"
f"[x % {int(monkey_data[3].replace('Test: divisible by ', ''))} != 0]"
),
}
)
return result
In run_monkeys each monkey is evaulated in several rounds. The mod argument keeps worry from going too large in part2.
def run_monkeys(monkeys: list[dict], rounds=20, mod=1):
for r in range(rounds):
for m in monkeys:
while m["stack"]:
m["inspected"] += 1
i = m["stack"].pop(0)
x = m["operation"](i)
monkeys[m["test"](x)]["stack"].append(x % mod)
return monkeys
Part 1
Find the product of the inspection count of the two busiest monkeys after 20 rounds, using divby=3.
def prod(x):
return reduce(operator.mul, x, 1)
def monkey_biz(monkeys: list[dict]):
return prod(sorted([m["inspected"] for m in monkeys], reverse=True)[:2])
print("Part 1: ", monkey_biz(run_monkeys(read_monkeys("input.txt", divby=3), rounds=20)))
Part 2
The initial version of part1 was very very slow, I never bothered running it for more than 800 rounds. This is because the worries becomes huge. The solution is to apply the modulus product over all monkeys, using the mod setting in run_monkeys (I had to consult some forums to get that right).
mod = prod([m["mod"] for m in monkeys])
monkeys = run_monkeys(monkeys=monkeys, rounds=rounds, mod=mod)
print("Part 2:", monkey_biz(monkeys))
Day 12 - Hill Climbing Algorithm
This was easily my favourite entry so far!
Click to expand Day12 solution
The data is a heightfield, with height as char: a(lowest) to z(highest). The path starts at S (height=a), and ends at E (height=z).
Sabqponm
abcryxxl
accszExk
acctuvwj
abdefghi
The function read_map parses the input integer heights (with a=0), extracts the start and end point, and gets the map size m x n. With make_graph the map is turned into an adjeceny graph, ensuring map bounds are kept and no steps are taken up more than 1 height unit. With this, bfs is implemented - a vanilla
Breadth First Search to find the shortest path from S to E. I found the deque being sufficiently fast for both parts.
import collections
def read_map(path: str):
with open(path, "r") as f:
data = [[ord(j) for j in i.strip()] for i in f.readlines()]
n, m = len(data), len(data[0])
start = next(
(i, data[i].index(ord("S"))) for i in range(n) if ord("S") in data[i]
)
end = next(
(i, data[i].index(ord("E"))) for i in range(n) if ord("E") in data[i]
)
data[start[0]][start[1]] = ord("a")
data[end[0]][end[1]] = ord("z")
data = [
[data[i][j] - ord("a") for j in range(m)] for i in range(n)
] # subtract a
return data, start, end, n, m
def make_graph(data, n, m):
graph = {}
for i in range(n):
for j in range(m):
graph[(i, j)] = set(
c
for c in [(i - 1, j), (i + 1, j), (i, j - 1), (i, j + 1)]
if 0 <= c[0] < n
and 0 <= c[1] < m
and data[c[0]][c[1]] - data[i][j] <= 1
)
return graph
def bfs(graph, start, end):
if start == end:
return [start]
done = {start}
queue = collections.deque([(start, [])])
while queue:
c, path = queue.popleft()
done.add(c)
for n in graph[c]:
if n == end:
return path + [c, n]
if n in done:
continue
queue.append((n, path + [c]))
done.add(n)
return None
Part 1
Part one is solved by the following code:
def part1(path):
data, start, end, n, m = read_map(path)
graph = make_graph(data, n, m)
sol = bfs(graph, start, end)
return len(sol) - 1
This is what the solution looks like:
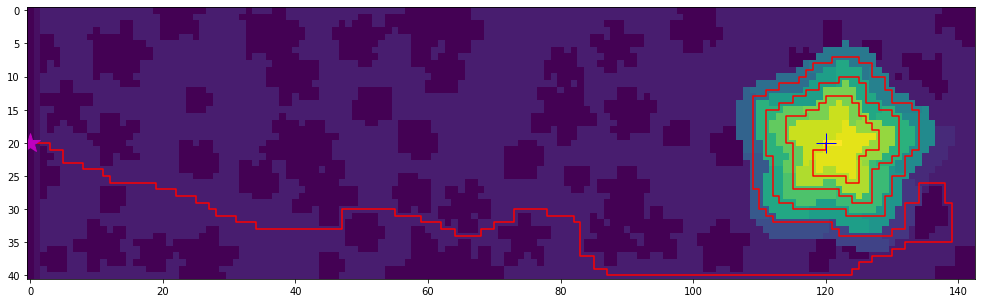
The figure was made using matplotlib
# data from read_map, sol from bfs
fig, ax = plt.subplots(figsize=(20,5))
ax.imshow(data)
ax.plot([s[1] for s in sol], [s[0] for s in sol], "r-")
ax.plot(sol[0][1], sol[0][0], "m*", ms=20)
ax.plot(sol[-1][1], sol[-1][0], "b+", ms=20)
Part 2
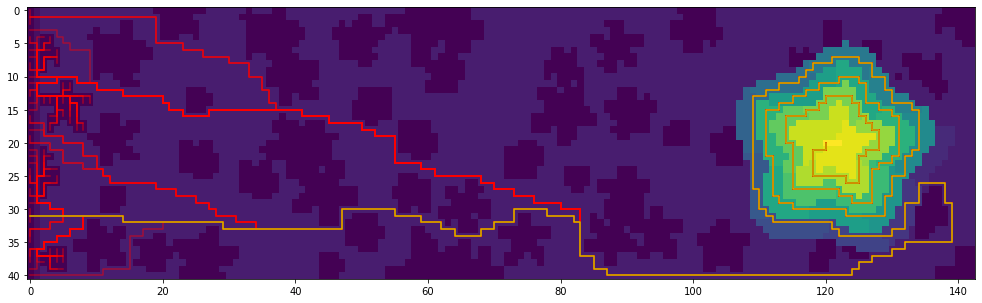
In part 2, any point at height a is used as the starting point.
def part2(path):
data, start, end, n, m = read_map(path)
graph = make_graph(data, n, m)
best = None
for start in [g for g in graph if data[g[0]][g[1]] == 0]:
sol = bfs(graph, start, end)
if not sol:
continue
if not best or len(sol) < best:
best = len(sol) - 1
return best - 1
This is what the solution looks like:
Day 13 - Distress Signal
Click to expand Day13 solution
Data are pairs of nested lists separated by blanks
[1,1,3,1,1]
[1,1,5,1,1]
[[1],[2,3,4]]
[[1],4]
This data is parsed to python lists in read_pairs.
def read_pairs(path: str) -> list:
with open(path, "r") as f:
lines = f.readlines()
return [
list(map(eval, (lines[i], lines[i + 1])))
for i in range(0, len(lines), 3)
]
Part 1
Task: compare pairs, and print the sum of indices of the pairs that are in order, as done in part1.
The comparison is done in compare. If anything is found in or out of order the comparison stops and returns the results. Pairs of int are in order if left < right and out of order right < left. List pairs are iterated over sequentially, integer items are compared like above, and the procedure is recursed for list items. Mixed pairs are comnverted to list pairs. If the left list still has items remaining the pair is ìn order, and if the right list still has items remaining it is out of order.
def compare(left, right):
for l, r in zip(left, right):
ints = tuple(map(lambda x: isinstance(x, int), (l, r)))
if all(ints):
if r == l:
continue
return l < r
result = compare([l] if ints[0] else l, [r] if ints[1] else r)
if result is not None:
return result
if len(left) == len(right):
return
return len(left) < len(right)
def part1(pairs):
return sum(i for i, pair in enumerate(pairs, 1) if compare(pair[0], pair[1]))
Part 2
Task: flatten pairs, add items [[2]] and [[6]], sort according to compare, and find the product of indices of [[2]] and [[6]].
Here I use functools.cmp_to_key to turn compare into a key function.
import functools
import operator
def prod(x):
return functools.reduce(operator.mul, x, 1)
def part2(pairs):
q = sorted(
[i for p in pairs for i in p] + [[[2]], [[6]]],
key=functools.cmp_to_key(lambda left, right: -compare(left, right)),
)
return prod([i for i, c in enumerate(q, 1) if c in ([[2]], [[6]])])
Somehow my comparator only works in negative, but it does work :)
Day 14 - Regolith Reservoir
Click to expand Day14 solution
Data represents a map with obstacles givens as vertical or horizontal line segments:
498,4 -> 498,6 -> 496,6
503,4 -> 502,4 -> 502,9 -> 494,9
In read_map this data is read in and transformed into a list of lines, each consisting of list of segments.
def read_map(path: str) -> list[list[tuple[int, int]]]:
result = []
with open(path, "r") as f:
return [
[tuple(map(int, x.split(","))) for x in line.split("->")]
for line in f.readlines()
]
This can easily by plotted with matplotlib as a LineCollection
def plot_map(ax, data):
ax.add_collection(LineCollection(data))
ax.autoscale_view() # See comment above, after ax1.add_collection.
ax.set(ylim=ax.get_ylim()[::-1])
ax.set_aspect('equal', 'box')
fig, ax = plt.subplots(figsize=(12, 8))
plot_map(ax, indata)
fig.tight_layout()
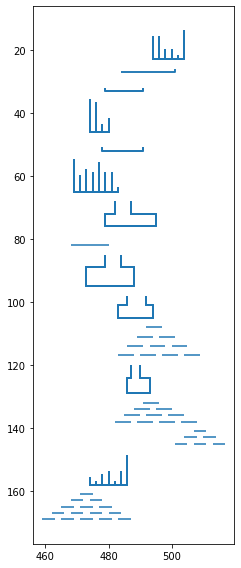
For the sand simulation it will be more convenient knowing which positions (pixels) are occupied.
def sign(x):
return (x > 0) - (x < 0)
def make_pixles(data):
pxl = {}
for segs in data:
for a, b in zip(segs[:-1], segs[1:]):
d = (b[0]-a[0], b[1]-a[1])
i = 1 if d[0]==0 else 0
si = sign(d[i])
pxl.update({((a[0], x) if i else (x, a[1])): True for x in range(a[i], b[i]+si, si)})
return pxl
def limits(pixels):
(min0, max0),(min1, max1) = map(lambda x: (min(x), max(x)), zip(*pxl))
return min0, max0, min1, max1
At (500,0) sand grains are produced and fall one at a time until they come to rest. Grains try to fall down, if down is blocked they go down-left, if that also is blocked down-right, and if everything is blocked it stops.
Tasks
Part1: How many sand grains come to rest before sand starts flowing into the abyss below?
Part2: How many sand grains come to rest before sand hole gets filled, assuming an infinite floor at max(mapy)+2
As sand propgagation is the same, really the only thing tat is different between the parts is the bounds checking. I solve that by adding missing floor pixels for part2.
def add_sand(pixels, min0, max0, min1, max1, part1):
s = (500, 0)
while (500,0) not in pixels:
t = next(
(
a
for a in ((s[0], s[1] + 1), (s[0] - 1, s[1] + 1), (s[0] + 1, s[1] + 1))
if a not in pixels
),
None,
)
if t:
s = t
if part1 and (s[1] > max1 or s[0] < min0 or s[0] > max0):
return False
if not part1 and (s[1] == max1+2):
pixels[s] = 1
return True
continue
pixels[s] = 2
return True
def fill(data, part1):
pixels = make_pixles(data)
min0, max0, min1, max1 = limits(pixels)
while add_sand(pixels, min0, max0, min1, max1, part1):
pass
return sum(p==2 for p in pixels.values())
To pretty print the map I added
def print_pixels(pixels, blank=".", full="#", sand="o"):
min0, max0, min1, max1 = limits(pixels)
for y in range(min1, max1+1):
print("".join((blank, full, sand)[pixels.get((x, y), False)] for x in range(min0, max0+1)))
print_pixels(pixels, blank="⬜", full="🟫", sand="🟨")
which gives this output for part 2 (using fancy box characters):
⬜⬜⬜⬜⬜⬜⬜⬜⬜⬜⬜🟨⬜⬜⬜⬜⬜⬜⬜⬜⬜⬜⬜
⬜⬜⬜⬜⬜⬜⬜⬜⬜⬜🟨🟨🟨⬜⬜⬜⬜⬜⬜⬜⬜⬜⬜
⬜⬜⬜⬜⬜⬜⬜⬜⬜🟨🟨🟨🟨🟨⬜⬜⬜⬜⬜⬜⬜⬜⬜
⬜⬜⬜⬜⬜⬜⬜⬜🟨🟨🟨🟨🟨🟨🟨⬜⬜⬜⬜⬜⬜⬜⬜
⬜⬜⬜⬜⬜⬜⬜🟨🟨🟫🟨🟨🟨🟫🟫🟨⬜⬜⬜⬜⬜⬜⬜
⬜⬜⬜⬜⬜⬜🟨🟨🟨🟫🟨🟨🟨🟫🟨🟨🟨⬜⬜⬜⬜⬜⬜
⬜⬜⬜⬜⬜🟨🟨🟫🟫🟫🟨🟨🟨🟫🟨🟨🟨🟨⬜⬜⬜⬜⬜
⬜⬜⬜⬜🟨🟨🟨🟨⬜🟨🟨🟨🟨🟫🟨🟨🟨🟨🟨⬜⬜⬜⬜
⬜⬜⬜🟨🟨🟨🟨🟨🟨🟨🟨🟨🟨🟫🟨🟨🟨🟨🟨🟨⬜⬜⬜
⬜⬜🟨🟨🟨🟫🟫🟫🟫🟫🟫🟫🟫🟫🟨🟨🟨🟨🟨🟨🟨⬜⬜
⬜🟨🟨🟨🟨🟨⬜⬜⬜⬜⬜⬜⬜🟨🟨🟨🟨🟨🟨🟨🟨🟨⬜
🟫🟫🟫🟫🟫🟫🟫⬜⬜⬜⬜⬜🟫🟫🟫🟫🟫🟫🟫🟫🟫🟫🟫
Day 15 - Beacon Exclusion Zone
Click to expand Day15 solution
Data is on this form:
Sensor at x=2, y=18: closest beacon is at x=-2, y=15
Sensor at x=9, y=16: closest beacon is at x=10, y=16
...
For the solution I need the manhattan distance between sensor and closest beacon. So I read in the data, parse as ints and compute the distance:
def distance(x):
return abs(x[0] - x[2]) + abs(x[1] - x[3])
def read_beacons(path: str) -> list[tuple[int, int], int]:
with open(path, "r") as f:
return list(
map(
lambda x: (x[0:2], x[2:4], distance(x)),
(
tuple(
int(i)
for i in re.split("; |, |=|:", line.strip())
if i.replace("-", "").isdigit()
)
for line in f.readlines()
),
)
)
Part 1:
Task: Count positions that are covered between the beacons and sensors for row 2000000
To solve this I fill all covered positions, taking care to remove Beacons from the count
def cover(row, beacons):
overlap = set()
for s, b, d in beacons:
dd = d - abs(s[1] - row)
if dd < 0:
continue
overlap.update(range(s[0] - dd, s[0] + dd + 1))
if b[1] == row:
overlap.remove(b[0])
return len(covered)
Part2
Now it asked to search for a single gap in coverage over the range (0, lim) in both x and y. I tried using the original cover function for this, but I only reached 6 rows / second. and with 4000000, I didn’t feel like waiting that long.
Instead, I keep track of the covered ranges [(x0, x1), … ] for a row at a time. When adding a beacon, I make sure to merge any overlapping coverages.
def calc_covers(row, beacons, lim):
covers = []
for s, b, d in beacons:
dd = d - abs(s[1] - row)
if dd < 0:
continue
x = max(0, s[0] - dd), min(lim, s[0] + dd + 1)
covers.append([x[0], x[1]])
if len(covers) == 1:
continue
# Now remove covers
covers.sort(key=lambda x: x[0])
idx = 0
for a in covers:
if covers[idx][1] >= a[0]:
covers[idx][1] = max(covers[idx][1], a[1])
else:
idx += 1
covers[idx] = a
covers = covers[: idx + 1]
if covers[0][0] == 0 and covers[0][0] == lim:
return covers
return covers
Now part2 is solved:
def part2(lim: int, beacons):
for row in range(lim):
overlap = calc_covers(row, beacons, lim)
if len(overlap) != 1:
return 4000000 * overlap[0][1] + row
This takes about 30s instead of something like 200h… I feel like I could have used an Interval Tree but my simple approach worked sufficiently fast for the problem at hand.
Day 16 - Proboscidea Volcanium
I really struggled with part2 of this problem…
Click to expand Day16 solution
The data is a maze of tunnels with valves that has a flow rate in units/minute.
Valve AA has flow rate=0; tunnels lead to valves DD, II, BB
Valve BB has flow rate=13; tunnels lead to valves CC, AA
This is nice to parse with re.split as follows.
import re
from typing import Iterator
VALVES_T = dict[str : tuple[int, list[int]]]
def read_valves(path: str) -> VALVES_T:
valves = {}
with open(path, "r") as f:
return {
v.split()[1]: (
int(re.split("rate=|; ", v)[1]),
re.split("valves|valve", v)[1].replace(",", "").split(),
)
for v in f.readlines()
if v.strip()
}
(later I realized this could be achived with a single split… but this works just fine as is).
Task 1
An explorer starts at valve AA, can walk for 1 minute through a tunnel, or open a valve for 1 minute. All valves start closed. What is the highest output throught the valves that can be achieved in 30 mins.
These possibilities are encoded in generate_steps:
def generate_steps(valves: VALVES_T, c: str, opened) -> Iterator[tuple(str, set[str])]:
# Explore tunnels
for v in valves[c][1]:
yield v, opened
# Open valve
if valves[c][0] > 0 and c not in opened:
yield c, opened | set((c,))
with which the tunnels can be explored using search:
def search(
valves: VALVES_T, start: str, steps: int, opened: set[str] = set()
) -> search_type:
seen = {start: 0}
queue = collections.deque([(1, [start], 0, opened)])
paths = []
while queue:
t, path, pressure, opened = queue.pop()
c = path[-1]
if t == steps:
paths.append((pressure, path, opened))
continue
if seen.get((t, c), -1) >= pressure:
continue
seen[(t, c)] = pressure
pressure += sum(valves[o][0] for o in opened)
queue.extend(
(t + 1, path + [i], pressure + (valves[c][0] if i == c else 0), o)
for i, o in generate_steps(valves, c, opened)
)
return max(paths)[0]
This works and givesd a result in less than a second.
Task 2
I spent a lot of time trying to adapt search for reusue, but I kept getting the wrong answer. At the end of the day i resorted to nested for loops. This was crazy slow for the input data set though. Frustrated enough, I picked up a quick and dirty pruning trick from llimllib.
def search_elephant(valves: VALVES_T, start: str = "AA", steps: int = 26) -> int:
frontier = [(0, (start, start), set())]
for i in range(0, steps):
if i > 5:
# it _works_ with my data...
# A priority queue would have been a little nicer
frontier.sort(reverse=True)
frontier = frontier[:5000]
update = []
for pressure, (a, b), opened in frontier:
pressure += sum(valves[o][0] for o in opened)
update.extend(
(pressure, (ia, ib), ob)
for ia, oa in generate_steps(valves, a, opened)
for ib, ob in generate_steps(valves, b, oa)
)
frontier = update
return max(frontier)[0]